The International Society for Biocuration (ISB) is offering 5 in-person travel grants for the Biocuration 2026 Conference in Cape Town, South Africa.
In-person awards cover up to 2,700 CHF in expenses, paid as reimbursements following the conference, meaning that awardees must pay their expenses and send receipts (including any for currency exchange costs) to the ISB following the conference.
In person awardees are also required to submit a recent photograph and a written report (minimum 100 words) about the outcomes of their attendance. These will be posted on the ISB website, newsletter, ISB mailing list, and promoted on social media (Bluesky, LinkedIn, Mastodon).
All awardees are expected to present either a talk or poster at the conference.
If you are a current ISB member, please provide the email address associated with your ISB membership.
The Executive Committee of the International Society for Biocuration (ISB) is pleased to open the call to host the 20th International Biocuration Conference in Asia/Oceania, preferably during April or May 2027, though nearby dates may also be considered.
Individuals and organizations interested in applying may do so by sending a proposal to the ISB Executive Committee (intsocbio@gmail.com) on or before August 31st, 2025.
The successful bidder will be notified by October 1st, 2025. The ISB Executive Committee will publicly announce the selected organization or individuals during the Annual General Meeting held virtually in October.
Applicants may later be asked to provide further details about the proposed venue, proposed dates, strategies for broad community engagement and fair gender representation, and more.
In a continued effort to bring our meeting to curators in all geographic regions, we encourage ISB members across the Asia/Oceania region to put forward proposals to bring the ISB meeting to your region once again, or for the first time!
This survey aims to gather and analyze information about the field of biocuration.
This survey is being conducted by the International Society for Biocuration (ISB) to identify potential gaps or inequities among biocurators and to identify areas where the ISB may be able to take actions to improve awareness of biocuration.
This is a follow-up with our community to assess the progress made since the we began surveying the community in 2017. The results from past surveys are available here: https://www.biocuration.org/dissemination/survey-results/ (see ISB Career Description Survey Results).
The resulting data will be aggregated and analyzed and shared with the community. No identifying information will be revealed in reporting results of this survey.
Thank you for your participation. The survey will close Friday, March 28th, 2025
Director of the Translational Data Analytics Institute, Director of Imageomics Institute, PI of AI and Biodiversity Change (ABC) Global Climate Center, Ohio State University.
Day 1, Session 1: Data Standards & Ontologies
Encouraging authors to use and cite data in public repositories; a publisher perspective.
Bastien Molcrette
Data Publications, Data Standards, Fair Data Principles, Public Data Resources
DO Spanish: enhancing DEI via a standardized workflow for translating ontology and website content
Lynn Schriml
Curation, Data Sharing, Disease, Ontologies
Harnessing Community Power for Long-Term Success of the Mondo Disease Ontology
Sabrina Toro
Curation, Data Standards, Disease, Ontologies
The Earth Metabolome Initiative Ontology
Tarcisio Mendes de Farias
Data Modeling, Knowledge Graphs, Omics Data, Ontologies
Director, Division of Bioinformatics, Director of the Gene Sequence, Function, and Health Laboratory Initiative, University of Southern California, PI Gene Ontology, PI PANTHER
Day 2, Session 1: Gene/Protein Functional Prediction
DisProt: The Manually Curated Resource for Intrinsically Disordered Proteins
M. Victoria Nugnes
Curation, Databases, Ontologies, Proteins
A Large Scale Crowdsourcing of the Fifth Critical Assessment of Protein Function Annotation
Iddo Friedberg
Annotations, Artificial Intelligence, Functional Protein Annotations, Public Data Resources
New Synteny visualizations on Xenbase
Malcolm Fisher
Annotations, Comparative Data, Genomes, Synteny
Day 2, Session 2: Gene/Protein Functional Prediction
Cross-species quantification of function annotations provides insights into disease-associated uncharacterized human genes
Parnal Joshi
Annotations, Comparative Analysis, Data Analysis, Functional Protein Annotations
Leveraging the AlphaFold Database for enhanced protein function annotation
Paulyna Magaña
Annotations, Functional Protein Annotations, Protein Structure Prediction, Proteins
Leveraging Large Language Models for Gene Summary Generation at the Alliance of Genome Resources
Valerio Arnaboldi
Large Language Models, Literature Mining, Automated Gene Summaries, Text Summarization
Life Cycle Events for Protein Family Models: Birth, Maturation, Cloning, Retirement
Daniel Haft
Bacteria, Data Sharing, Functional Protein Annotations
Semi-automated curation of post-translational modification relationships using automated knowledge extraction and assembly
Benjamin Gyori
Artificial Intelligence, Curation, Databases, Literature Mining
Characterization and automated classification of sentences in the biomedical literature: a case study for biocuration of gene expression and protein kinase activity
Daniela Raciti
Curation, Machine Learning, Community Curation, Sentence Classification
Enhancing the SIB Literature Services with annotations to support biocuration
Deborah Caucheteur
Annotations, Curation, Data Analysis, Literature Mining
Protein structure enrichment through text mining
Melanie Vollmar
Annotations, Literature Mining, Natural Language Processing, Protein structures
Enhancing data annotation in ChEMBL for robust analyses
Sybilla Corbett
Annotations, Curation, Fair Data Principles, Natural Language Processing
Day 2, Session 4: Glycans
Glycan Archetypes: definitions, implementations and applications for standardizing glycan structure data
Kiyoko Aoki-Kinoshita
Data Standards, Databases, Glycans, Ontologies
BiomarkerKB: Biomarker-centric data modeling and knowledge integration for translational research
Raja Mazumder
Curation, Databases, Glycans, Knowledge Graphs
Inferring Tissue and Cell-type Glycosyltransferase Specificity from Single-Cell Gene Expression Data
The Executive Committee of the International Society for Biocuration (ISB) would like to once again invite tenders to host the 19th International Biocuration Conference in Europe during the Northern Spring or Summer of 2026.
Individuals and organizations interested in applying may do so by sending a proposal to the ISB Executive Committee (intsocbio@gmail.com) on or before August 31st, 2024.
The successful bidder will be notified by October 1st, 2024. The ISB Executive Committee will publicly announce the selected organization or individuals during the 18th International Biocuration Conference, held in Kansas City, MO, USA in April, 2025.
Format:
Proposals should be short; length should not exceed one side of an A4 or US letter size sheet, using 11 point font. The proposal should contain:
The name and institution of the local organizer
Details of the proposed venue for at least 150 participants, if the venue has less space please provide plans for hybrid attendance. Typical numbers have not exceeded 350 participants.
The range of dates available for the conference. Previous conferences typically have 3-4 days of main conference agenda and 1-2 days of workshops. Dates should not overlap with local holidays.
A brief outline of a strategic plan to attract a broad range of participants from the Biocuration community
As fair gender representation is positively encouraged by the ISB; we would also like to know how the applicant intends to accomplish this.
In a continued effort to bring our meeting to curators in all geographic regions, we strongly encourage ISB members in Europe and Africa to put forward proposals to bring the ISB meeting to your region once again, or for the first time!
Held on September 2, 2022, the Biocuration Careers Workshop was the third and final installment of the International Society for Biocuration (ISB) virtual conferences in 2022. The workshop’s aim was to determine ways that ISB can assist Biocurators with career progression.
Organized and led by Nicole Vasilevsky, Lead Biocurator at the University of Colorado Anschutz Medical Campus, the workshop was facilitated by four field experts: Mohammad Hosseini, Kristi Holmes, Mary Ann Tuli, and Randi Vita.
To set the stage, the diverse set of job titles and roles collected as part of the 2020-2021 ISB survey were presented, as well as current job openings on the ISB website were discussed. One of the key ways the ISB helps biocurators in finding a new position is by posting job openings in the biocuration field. However, the job titles and descriptions of these positions can vary a great deal, which can be confusing for hiring managers and problematic for junior biocurators or those updating their resumes and looking to change positions.
Biocurators face some unique challenges with tracking our contributions to science. While it is not unusual for some biocurators to successfully work in their field without being a co-author of peer-reviewed articles, some biocurators might not always receive their due credit; making career advancement difficult, especially in academic settings where publications are viewed as the main proof of success. Mohammad Hosseini of Northwestern University presented Contributor Roles, an innovation developed to describe individual contributions to research. By providing a standard list of roles to specify individual contributions to publications, Contributor Roles enhance the transparency and consistency about the reporting of conducted tasks, and accordingly, improve the attribution of credit and responsibilities. The CRediT taxonomy is the most widely adopted Contributor Role schema, offering 14 standard roles, one of which is Data Curation, defined as: “Management activities to annotate (produce metadata), scrub data and maintain research data (including software code, where it is necessary for interpreting the data itself) for initial use and later re-use” (NISO 2022). The Contributor Role Ontology (CRO) is an extension of CRediT to highlight individual contributions to research. Although CRO provides more granularity with ten specific data roles (e.g., data aggregation, data integration, data modeling, data quality assurance), the biocurator roles are not similarly detailed. Mohammad also illustrated how publications with datasets stored in public repositories often do not adequately attribute the associated data processing efforts conducted by biocurators. Clarifying these roles can improve future attribution of credit and responsibilities.
Kristi Holmes, professor of Preventive Medicine and the director of Galter Health Sciences Library at Northwestern University shared ways to track scholarly products, including the traditional metrics that are typically captured on a CV, as well as other research products. By highlighting roles that biocurators play in pushing data-driven research forward, she highlighted the importance of tracking and assigning credit to biocurators in terms of understanding the work that is required to drive research, and ways those contributions can be described more accurately using a narrative approach.
Randi Vita from the La Jolla Institute for Immunology described the generic job description for a biocurator that was drafted as part of a previous ISB workshop in 2018, illustrating how diverse these positions can be. She stressed how different specialized skills are valuable to these positions and hiring managers, but are often overlooked when job candidates are polishing their CVs.
Understanding the wide range of roles that biocurators play in research projects and programs is critical to understand research process itself. The workshop facilitated a brief exploration of relevant topics such as standardization of job titles to support biocurators’ career progression, especially in academic settings wherein contributions are quantified and necessary for promotion, as well as novel and relevant credit and attribution for biocurators. Moving forward, the ISB could provide an excellent platform to advocate for more accurate and encompassing biocurator roles.
Help us continue this discussion and inform future activities:
The ISB would like to collect titles and qualifications, metrics and accomplishments for different career levels: https://bit.ly/3PvP9uu
Weigh in on future workshop ideas:
How do you get a job as a curator?
How do you write your resume/CV?
How do you write a job description for a curator?
Answer the study question: Are biocurator positions hard to fill? Could we get stats on how long biocuration jobs are open?
The 1st session of ISB2022 Biocuration Virtual Conference will take place on Thursday, April 7th 2022 at 8 – 10.30 am PT / 11 – 1.30 pm ET / 4 – 6.30 pm BST / 5 – 7.30 pm CET.
Check out the panelists and speakers of our 1st session here!
The fourth and final session of the ISB2021 14th annual conference (virtual) took place on October 5th, 2021, featuring the Annual General Meeting (i), a Panel Discussion on Strategic Planning with former ISB Executive Committee (EC) members (ii), talks from the Biocuration Awards recipients in 2021 (iii) and a Poster Session (iv).
During the Annual General Meeting, Nicole Vasilevsky, chair of the ISB EC, talked about the current status of ISB and the future directions of the Society. Four invited Panelists joined the Panel Discussion on Strategic Planning: Pascale Gaudet, Mike Cherry, Andrew Su and Monica Munoz-Torres, all of them being former members of the Executive of ISB. Finally, talks from the recipients of this year’s Biocuration Awards were presented: Amos Bairoch (2021 Exceptional Contribution to Biocuration Award) and Anne Niknejad (2021 Biocuration Award).
A Poster Session was carried out in gather.town, on a dedicated space entirely set up for the ISB, and followed by a social hour for ISB members and conference participants to interact and exchange ideas.
Annual General Meeting
The talk – led by the ISB EC Chair Nicole Vasilevsky – started with an overview of the current ISB Executive Committee, composed by nine members, that in 2020-2021 included Nicole Vasilevsky, (USA, Chair), Ruth Lovering (UK, Secretary), Robin Haw (Canada, Treasurer), Rama Balakrishnan (USA), Frederic Bastian (Switzerland), Jane Lomax (UK), Randi Vita (USA), Mary Ann Tuli (UK), and Sandra Orchard (UK). Three members, Sandra, Frederic and Jane, concluded their mandate in the ISB EC, while Mary Ann was re-elected along with three newly elected ISB members for the 2021-2024 term: Federica Quaglia, Sushma Naitani and Parul Gupta.
The ISB EC work in the past year included also the activities of several subcommittees, composed by ISB EC members and external members too:
Outreach and Training (Chair: Randi Vita)
IT infrastructure (Chair: Ruth Lovering)
Fellowships and Awards (Chair: Frederic Bastian)
Conference coordination (Co-chair: Rama Balakrishnan, Sue Bello)
Elections (Officer: Petra Fey)
Equity, Diversity and Inclusion
The ISB was founded in 2009, and since then the main goals of the society have been to promote the work of biocurators and encourage best practices in biocuration, and to foster communications and connections amongst the members. To this end, there are formal memberships in the society – currently including 232 members – although anybody in the community is welcome to participate in most of the activities. Relevant information on how to join the society (https://www.biocuration.org/membership/membership-levels/) and on the benefits associated with the ISB membership (https://www.biocuration.org/membership/join-isb/) can be found on the website.
A report of ISB finances for the last year, 2020, shows that we have collected over 7000 CHF – the society is based in Switzerland – and the expenditures include sponsorships and some administrative fees and taxes while currently operating on a balance of over 121.000 CHF. The ISB offers travel fellowships, funds attendees to join our conferences (when meeting in person), but also funds micro-grants and various proposals including smaller gatherings for curators to meet and work together, e.g. to visit another group and learn about new techniques or workflows. For members of the ISB we offer a discount on the publications in our affiliated journal, Database: The Journal of Biological Databases and Curation (https://academic.oup.com/database). To promote the work of our members in the society and in the field of biocuration we have a mailing list and a quarterly newsletter – organized by Mary-Ann Tuli – to communicate and disseminate information to our community of over 700 members. Finally, the ISB Twitter account (https://twitter.com/biocurator) actively advertises news related to the society and to the biocuration field. There are also two dedicated ISB awards that we offer yearly, the exceptional contribution to biocuration award and the biocuration career award, the recipients this year being Amos Bairoch and Anne Niknejad.
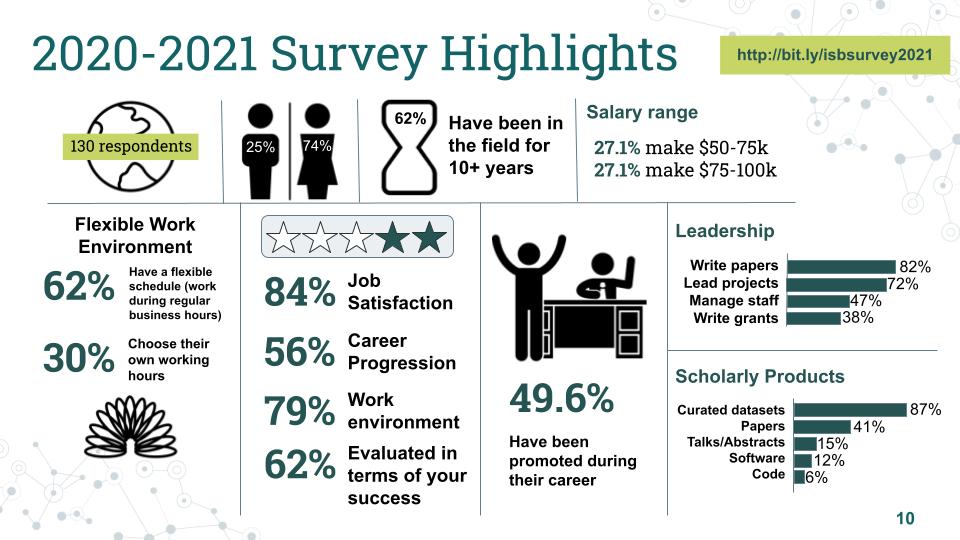
In an effort to assess the work of biocurators the ISB sent out a survey during the last year, that shed light on biocuration-related work positions, satisfaction, work environment, leadership levels and scholarly products. Highlights are shown below and the results of the survey are available here.
The survey had over 130 respondents – 74% out of them are women and 25% men. Interestingly, the majority of respondents have been in the field for over 10 years (62%), suggesting their satisfaction and identifying biocuration as a stable career choice. For what concerns salary range of biocurators, half of respondents (54.2%) earns between 50 and 100k a year in US dollars. Further inquiring on the the work environment highlighted some flexibility in the work schedule (identified as flexibility during regular business hours) for 62% biocurators, while 30% are actually able to choose their own working hours. Among the biocurators involved in the survey, 84% are satisfied with their job, with their work environment (79%), professional success (62%) and career progression (56%) – people are overall highly satisfied – with under half of respondents (49.65%) that have also been promoted during their career. In terms of leadership opportunities, we were able to identify four main areas of leadership for biocurators, namely manuscript drafting and publication (82%), project leading (72%), staff management (47%) and writing grants applications (38%), pointing up to the involvement of biocurators in managerial positions and further supporting the high rate of satisfaction in biocuration careers. Finally, the survey identified the five main types of scholarly products generated by biocurators, i.e. curated datasets (87%), publications (41%), talks at conferences (15%), softwares (12%) and codes (6%), identifying a need for ways that could increase the articles published by biocurators.
Panel Discussion on Strategic Planning with former EC committee members at the Biocuration2021 virtual conference
The Panel Discussion on Strategic Planning was joined by former members of the Executive Committee of ISB, Pascale Gaudet, Mike Cherry, Andrew Su and Monica Munoz-Torres.
Andrew Su: Professor at Scripps Research. Representative projects include the Gene Wiki, and BioThings Explorer. He served on the ISB from 2016-2019.
Mike Cherry: Professor of Genetics at Stanford University. He oversees the Saccharomyces Genome Database. As well, he is involved in ENCODE (Encyclopedia of DNA elements), Gene Ontology Consortium, Alliance of Genome Resources, RegulomeDB, and Lattice: Human Cell Atlas. He served on the ISB from 2010-2016 and acted as chair from 2015-2016.
Pascale Gaudet: Senior Project Manager in the Swiss-Prot group of the SIB Swiss Institute of Bioinformatics. Project Manager of the Gene Ontology project. She is a founding member of the ISB and acted as Chair of the ISB Executive Committee from 2009 to 2013.
Monica Munoz-Torres: Associate Research Professor in the Center for Health Artificial Intelligence at the University of Colorado Anschutz Medical Campus. Director of Operations for the Center for Cancer Data Harmonization (for NIH/NCI) and Program Director for the Phenomics First Resource (an NHGRI CEGS) and the Monarch Initiative. She served on the ISB Executive Committee from 2012 through 2017, as Secretary in 2012-2016 and as Chair in 2016-2017.
The discussion started with the panelists’ reflections on the very beginning of the ISB and on how those dreams and hopes became reality over the years, while continuously looking at the future of biocuration and at new ways to improve our profession by serving in the Society.
The ISB has a well-established central role in fostering and building connections among the members, in first place thanks to the meetings that took place over the years and now including additional venues that facilitate our interactions, such as a mailing list, newsletter, our Twitter account and a dedicated Slack workspace. Awards and microgrants have also played a crucial role in raising awareness on the centrality of biocuration careers inside the scientific community and in supporting knowledge-exchange between biocurators from different groups. It is fundamental to reach a better appreciation of biocuration as a means to advance scientific research by making research data shareable and accessible in a standardized format, especially at the level of funding agencies. These topics have a particular relevance when paired with the advancements in machine learning and artificial intelligence: these indeed can not replace expert literature curation, vice versa machines can be supported by biocurators via the use of carefully curated high quality annotations.
Over the years following its foundations, the ISB has been growing to be more inclusive and diverse and focused on developing and implementing a code of professional conduct. The introduction of several subcommittees, composed not only of EC members but of the greater ISB members too, raised the opportunity to increase the ability to volunteer in the activities of the ISB. The society is now also exploring new ways to cover a variety of professional experiences by engaging biocurators in poorly-represented geographical areas and by welcoming graduate students, by considering introduction of a dedicated “students section”.
Our society also benefited from the efforts of the ISB EC back in 2008, with the establishment of a dedicated journal, Database: The Journal of Biological Databases and Curation (https://academic.oup.com/database). This peer-reviewed journal is now at the forefront in the publication of biocuration-related articles, providing also a 20% discount on publication fees to members of the ISB. The existence of a specific journal for biocuration positively affected our field – it was usually hard to publish in traditional scientific journals – and provided our community with a specific venue to publish our research work. It is worth considering the option to provide microgrants to cover publication costs in Database, in those situations where a restricted access to funding prevents the submission of manuscripts to a scientific journal. Finally, an additional option would be considering the micropublication system, where no publication cost is involved while still allowing to make research data public (https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5836261/, https://www.micropublication.org/).
Although a result of the ongoing global pandemic, this year’s virtual conference overall received great feedback as it has been more accessible by allowing everyone to attend, even those who could not afford to travel e.g. due to family commitments. It was therefore proposed to keep on maintaining some virtual events even once the restrictions related to the pandemic will be lifted and the conference will resume in presence.
Finally, panelists unanimously agreed on the relevance of the ISB in supporting and promoting career development for biocurators, with a great starting point being the establishment of formal training opportunities and professional certificates that did not previously exist in the field. At the same time, creating, maintaining and sharing FAIR training materials (Goblet, ELIXIR TeSS) should be even more supported and pursued, while also providing dedicated learning sessions where to present them.
All these directions will play a crucial role in our job security and will make room for professional development of biocuration careers, actively supported by the International Society for Biocuration.
Search on the site
Log In
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.
Read More
Cookies are small text files that can be used by websites to make a user's experience more efficient. The law states that we can store cookies on your device if they are strictly necessary for the operation of this site. For all other types of cookies we need your permission. This site uses different types of cookies. Some cookies are placed by third party services that appear on our pages.
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Name
Domain
Purpose
Expiry
Type
wpl_user_preference
www.biocuration.org
WP GDPR Cookie Consent Preferences.
1 year
HTTP
PHPSESSID
www.biocuration.org
PHP generic session cookie.
54 years
HTTP
__stripe_mid
www.biocuration.org
For processing payment and to aid in fraud detection.
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.